Program
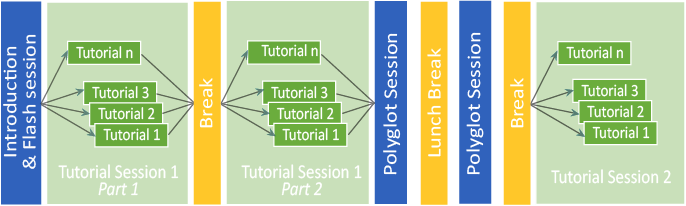
The workshop follows a novel massively parallel format. After a joint introduction
Introduction Slides
multiple parallel tutorial sessions are held.
Each tutorial is 1,5 hours in length and will be repeated so that participants can attend two tutorials.
In the tutorial sessions the following systems, which received the most votes, will be presented:
Polyglot Datamanagement Session
The traditional tags for databases have been rendered obsolete since new data management technologies
emerge with a combination of traditional and new capabilities that are transforming the database world.
There are many open research challenges in which many different data stores coexist and even ecosystems
and architectures based on multiple data stores, such as the lambda architecture. The new technologies
have brought new data models and query languages more appropriate for certain kinds of problems such as
key-value data stores, document data stores, and graph databases. In this context developers must deal
with this data diversity in order to get insights and knowledge from the different data stores. Moreover,
guaranteeing consistency across data stores has become a major issue due to the polyglot persistence trend.
This session will present different technologies in this evolving arena of new data management technologies
combining multiple capabilities.
Polyglot Databases Session@BOSS-VLDB
Program Outline:
| 9:00 - 9:15 | Introduction |
| 9:15 - 9:45 | Flash Session |
| 9:45 - 10:30 | Tutorial Session 1 (Part 1) |
| 10:30 - 11:00 | Break |
| 11:00 - 12:00 | Tutorial Session1 1 (Part 2) |
| 12:00 - 12:30 | Polyglot Session (Part 1) |
| 12:30 - 14:00 | Lunch Break |
| 14:00 - 15:30 | Polyglot Session (Part 2) |
| 15:30 - 16:00 | Break |
| 16:00 - 17:30 | Tutorial Session 2 |
Details of the Presented Systems
Apache Flink
Real time data stream processing has become a critical building block for many modern
businesses. In stream processing, the data to be processed is viewed as continuously
produced series of events over time. This departs from the
well studied batch processing paradigm where data is viewed as static. In fact,
batch processing problems can be viewed as a subclass of stream processing ones,
where streams are finite
Building on this principle, Apache Flink has emerged as one of the most
successful open-source stream processors, with an active community of 190 contributors
from both industry and academia and several companies deploying it in production.
At its core Flink has a stream processing engine that allows for robust, high-throughput,
low latency processing of out-of-order streams, while providing exactly-once semantics
for stateful computations.
In this tutorial the attendees will have the opportunity to learn about the most important
notions introduced by the stream processing paradigm, get introduced to the architecture
and the main building blocks of Flink and get exposed to different features of Apache Flink
through representative applications.
Presenters:
- Konstantinos Kloudas (dataArtisans)
- Jonas Traub(TU Berlin)
- Vasia Kalavri (KTH Stockholm)
Resources:
Apache SystemML
Apache SystemML aims at declarative, scalable machine learning (ML). Data scientists express their custom analytics in a high-level language,
including linear algebra and statistical functions, which simplifies the implementation of new or customization of existing ML algorithms.
These algorithms can be run without modifications in a single node (scale-up), or on a cluster using MapReduce or Spark (scale-out).
The SystemML language is expressive enough to cover a broad class of ML algorithms including descriptive statistics, classification, clustering,
regression, matrix factorization, dimension reduction, and deep learning for training and scoring. SystemML's cost-based compiler
then automatically generates hybrid runtime execution plans that are composed of single-node and distributed operations depending on data
characteristics such as data size/shape (e.g., tall and skinny or wide matrices), data sparsity (e.g., dense or sparse), and cluster characteristics
(e.g., cluster size, and memory configurations). The benefits of declarative ML include (1) increased productivity of data scientists due to a data-scientist-centric
algorithm specification, (2) algorithm reusability and simplified deployment for varying data characteristics and runtime environments, and (3) good runtime
performance due to automatic optimization of execution plans given data and cluster characteristics.
In this tutorial, we will discuss SystemML usecases, example ML algorithms,
and various APIs for different deployments. Along this user-level tutorial, we will primarily focus on a deep-dive into
SystemML's architecture, optimizer including rewrites and cost model, and internals to help understand performance characteristics
and limitations as well as enable the database community to extend SystemML for further research.
Presenters:
- Matthias Boehm (IBM Research - Almaden)
- Shirish Tatikonda (Target Corp.)
- Berthold Reinwald (IBM Research - Almaden)
Resources:
HopsFS and ePipe
HopsFS is a next generation distribution of the Hadoop Distributed File System (HDFS) that replaces HDFS' single node in-memory metadata
service with a distributed metadata service built on a NewSQL database (MySQL Cluster). By removing the metadata bottleneck, HopsFS improves capacity and throughput
compared to HDFS. More interestingly, HDFS' metadata is now in a distributed database that supports mechanism for the efficient export of metadata to other systems.
Both HDFS and HopsFS, like other POSIX compliant filesystems, lack support for efficient free-text search of the filesystem namespace. HopsFS stores
the metadata normalized in relational tables in MySQL Cluster, and, as such, the database cannot efficiently handle queries such as "what are the largest files in the system" or "list
all files with the prefix 'hopsfs'". Moreover, HopsFS, can extend metadata for inodes (files or directories) by adding new table(s) with a foreign key to the inode to ensure the
integrity of extended metadata. We have used extended metadata to implement features such as erasure-coded replication. We have a solution to the problem of free-text search for
both namespace metadata and extended metadata by developing an efficient and highly available eventually consistent replication protocol from MySQL Cluster to Elasticsearch. Our system,
called ePipe, leverages the event API for MySQL Cluster enabling us to sends process batches of transactions filtered by table name from the single source of truth, MySQL Cluster.
These transactions contain mutations to metadata and extended metadata that will be indexed by Elasticsearch. ePipe maintains the consistency of the system by making sure that the events
coming from the database are processed in order. As ePipe only processes mutations, it has to read actual data from the database which it does using only efficient primary key or
partition-pruned index-scans. We also added a new RPC to HopsFS (not found in HDFS) to turn on or off metadata for inodes or inode subtrees. Our Hadoop platform has been presented
at Hadoop Strata (Startup Showcase in San Jose as well as London), and the Data Science Summit (both Israel and San Francisco).
Tutorial Outline
The tutorial will guide users through the deployment and setup of Hops Hadoop on AWS, including Elasticsearch using an automated installation platform based on Chef. After installation, users will be guided through the design of the Hops concepts of projects and datasets using our Hadoop-as-a-Service platform, www.hops.site. Users will create a project and import some public datasets, share datasets with one another, and show how to request access to a dataset. Users will use Elasticsearch free-text search to search the system. We will also show users how they can make their datasets globally visible and downloadable by any other registered Hops cluster using peer-to-peer technology.
Presenters:
- Mahmoud Ismail
- Gautier Berthou
Resources:
LinkedIn's Open Source Analytics Platform
Modern web scale companies have outgrown traditional analytical products due to
challenges in analyzing massive scale, fast moving datasets at real-time latencies.
As a result, the traditional integrated analytics database has been unbundled into its
component architectural pieces that span data ingestion, data processing and analytics
query serving. This unbundling has spawned dozens of open source and commercial products
that specialize in solving each individual phase (ingest, process, serve) of this data lifecycle.
This in turn has created new challenges in adopting and integrating each of these systems to create
a high-functioning real-time analytics stack. In this tutorial, we showcase the open-source LinkedIn
Big Data Analytics Stack composed of Kafka, Gobblin, Hadoop and Pinot. Kafka and Hadoop are
well understood parts of this puzzle already w.r.t streaming and batch data storage and compute.
However, ingesting and managing this data and serving it efficiently at scale for analytics use-cases
data ingestion at scale with Gobblin and high-performance real-time distributed OLAP serving with Pinot.
Gobblin is an open source platform for large scale data management that is under active development at LinkedIn. It is designed with data diversity
in mind, and as such, it can move data between a large variety of data sources and sinks ranging from HDFS, Kafka, RDBMS', REST sources, FTP/SFTP servers etc. It abstracts away logic common to all data ingestion pipelines such as data discovery, error handling, quality checking and state management. Gobblin is the primary Hadoop data ingest, replication and data management tool at LinkedIn processing well over 50TB of data daily. Standardizing on Gobblin has enabled LinkedIn to add data sources quickly (data relevant for analysis is almost never known a priori), comply with regulatory requirements related to data handling and provide data quality guarantees for data consumers; features that are absolutely essential for any data ecosystem.
Pinot is a real-time distributed OLAP data store, which was built at LinkedIn to deliver scalable real time analytics with low latency. It implements
the Lambda architecture and can ingest and merge data from batch data sources (such as Hadoop and flat files) as well as streaming sources (such as Kafka). Pinot is optimized for analytical use cases on immutable append-only data and offers data freshness on the order of a few seconds. In production, Pinot scales horizontally to hundreds of tables, thousands of events per second, hundreds of machines and thousands of queries per second while responding to complex queries within tens to hundreds of milliseconds. At LinkedIn, Pinot powers more than 50 site facing and internal applications, including flagship applications like "Who Viewed My Profile" and "Company and Job Analytics".
Tutorial Outline
Gobblin Introduction and Architecture
- Gobblin use-cases
- Overview of Gobblin architecture
- Deep dive into select Gobblin features (e.g. data transformation)
- Kafka Ingestion pipeline
- MySQL ingestion pipeline (time permitting)
Pinot Introduction and Architecture
- When to use Pinot?
- Overview of Pinot architecture
- Managing Data in Pinot
- Data storage format
- Handling Real-time data in Pinot
Hands-on Tutorial
In the tutorial we will setup a Kafka ingestion pipeline, consuming data from a local Kafka server, performing format
transformation, identifying bad records, performing a quality check on the ratio of bad records, and writing the data to time partitioned files in HDFS. If time permits, we will show how the same Gobblin flow can also ingest data from a completely different source: MySQL. We will then load this data (both real-time and batch) into a local Pinot instance where the data can be queried interactively.
Attendees will learn how to:
- Setup a local Kafka server.
- Setup a local Gobblin installation that consumes Kafka data.
- Setup a parallel pipeline that ingests data from MySQL (time permitting).
- Load Pinot with batch data from HDFS and real time data from Kafka.
- Perform analytics queries against Pinot.
- Performance tuning and best practises.
Technologies Used
- Kafka (Will provide a script for a quick local Kafka setup and a data generation script)
- Gobblin
- Pinot
- Hadoop (MapReduce, HDFS)
Presenters:
- Issac Buenrostro (LinkedIn Corp.)
- Jean-Francois Im (LinkedIn Corp.)
- Vasanth Rajamani (LinkedIn Corp.)
- Ravi Aringunram (LinkedIn Corp.)
Resources:
rasdaman
Massive multi-dimensional arrays appear as spatio-temporal sensor, image, simulation output, or statistics "datacubes" in a variety of domains in Earth, Space, and Life sciences, but also Social sciences as well as business. Understandably, arrays as a datatype come along with a distinct set of challenges in data modelling, analytics, optimization, and maintenance. Array Databases have set to address these facets and provide modern, fast, and scalable services on such array data. rasdaman ("raster data manager") is the pioneer Array Database bundling novel processing techniques in a user-friendly package with standards-compliant interfaces. As of today, rasdaman is a mature system in operational use on hundreds of Terabytes of timeseries datacubes; installations can easily be mashed up securely, thereby enabling large-scale location-transparent query processing in federations of any combination from typical desktop machines, to cloud nodes, datacenter supercomputers, and even cubesats. Its concepts have shaped international Big Data standards in the field, including the forthcoming array extension to ISO SQL, many of which are supported by both open-source and commercial systems meantime. In the geo field, rasdaman is a reference implementation for the Open Geospatial Consortium (OGC) Big Data standard, WCS, now also under adoption by ISO.
Tutorial Outline
In this tutorial we present the open-source rasdaman Array DBMS.
The following topics are covered:
- Installation & deployment: Standard RPM/DEB packages? VM images? Docker? Pick your favorite.
- Data modelling and concepts: What kind of data is supported? Can it mix with the standard relational model?
- Query language: What are the capabilities of the rasdaman query language? Can we express typical array analytics queries, and can it efficiently and reliably deliver results?
- Storage management: Single array datacubes can reach hundreds of Terabytes in size; learn how rasdaman scales to support such volumes with adaptive tiling and indexing strategies. Throughout we keep it interactive and hands-on for the audience, with real-time examples and use-case driven queries both locally and via Internet.
Tutorial technology
Participants will need to follow one of the options below:
- Linux OS in order to natively install Debian or RPM rasdaman packages;
- Virtual Machine software (e.g. VirtualBox), so that a VM image which has rasdaman preinstalled can be utilized;
- Browser with internet connectivity so that they can play with a remote rasdaman server available during the tutorial.
Presenters:
- Dimitar Misev (Jacobs University, Bremen)
Resources:
RHEEM
Bored of keep moving your app to the newest data processing platform to achieve high performance? Tired of dealing with a zoo of processing platforms to get the best performance for your analytic tasks? Then, this tutorial is for you!
Indeed, we are witnessing a plethora of innovative data processing platforms in the last few years. While this is generally great, leveraging these new technologies in practice bears quite some challenges, just to name a few, developers must: (i) find among the plethora of processing platforms the best one for their applications; (ii) migrate their applications to newer and faster platforms every now and then; and (iii) orchestrate different platforms so that applications leverage their individual benefits.
We address these issues with RHEEM, a system that enables big data analytics over multiple data processing platforms in a seamless manner. It provides a three-layer data processing abstraction whereby applications can achieve both platform independence and interoperability across multiple platforms. With RHEEM, dRHEEMers (RHEEM developers) can focus on the logics of their applications. RHEEM, in turn, takes care of efficiently executing applications by choosing either a single or multiple processing platforms. To achieve this, it comes with a cross-platform optimizer that allows a single task to run faster over multiple platforms than on a single platform.
"...You may say I'm a dRHEEMer. But I'm not the only one. I hope someday you'll join us..."
- John Lennon -
Tutorial Outline
We plan a tutorial where participants are the main players and can interact with the speakers at any time. Tentatively, our tutorial will be as follows.
Introduction
In this first part of the tutorial, we will introduce the main concepts and rationale design behind RHEEM. This will allow participants to get familiar with the RHEEM paradigm.
Setting Up
After introducing participants to Rheem, we will guide them through the installation and set up of RHEEM to get ready to code their first application.
Building Up Your App
At this stage of the tutorial, we will show to users how one can easily develop and run an application on top of RHEEM. We will recap the main concepts in a hands-on exercise. In particular, we will see how to abstract and implement an application, how to support new functionalities by adding RHEEM operators, how to achieve higher performance by adding execution operators, and how to make the optimizer aware of the added operators.
Setting Up
After introducing participants to Rheem, we will guide them through the installation and set up of RHEEM to get ready to code their first application.
Machine Learning
We will conclude this tutorial by summarizing all main concepts using ML4all, our machine learning system built on top of Rheem and used by a big airline company from the middle-east. We will also leverage this application to walk participants through advanced features of RHEEM.
Presenters:
- Zoi Kaoudi (Qatar Computing Research Institute)
- Sebastian Kruse (Hasso Plattner Institute, Germany)
- Jorge-Arnulfo Quiané-Ruiz (Qatar Computing Research Institute)
Resources:
Workshop Organization
Workshop Chair:
- Tilmann Rabl, TU Berlin, rabl@tu-berlin.de
- Sebastian Schelter, Amazon, sseb@amazon.com
Polyglot Chair:
- Patrick Valduriez,INRIA France, patrick.valduriez@inria.fr
- Marta Patiño, Universidad Politecnica de Madrid, mpatino@fi.upm.es
Advisory Committee:
- Michael Carey, UC Irvine
- Volker Markl, TU Berlin
Selection Process
Important Dates
-
Call for tutorials: Open until June 1.
In order to propose a tutorial, please email
- a short abstract with a brief description of the system,
- an outline of the planned tutorial,
- the technology used for the hands on tutorial,
- a list of presenters involved,
- and a link to the website of your system
to boss@dima.tu-berlin.de - Public vote: will be open for two weeks until July 6.
- Accepted presenters: will be notified by July 15.